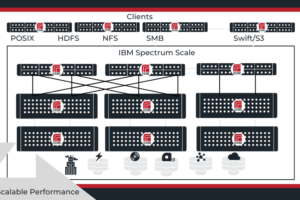
RAID Inc. + Spectrum Scale Solutions
Enterprises and organizations are creating, analyzing and storing more data than ever before. Those that can deliver insights faster while managing rapid infrastructure growth are the leaders in their industry. In delivering those insights, an organization’s underlying storage must support new-era big data and artificial intelligence workloads along with traditional applications while ensuring security, reliability and high performance. IBM Spectrum Scale™ meets these challenges as a high-performance solution for managing data at scale with the distinctive ability to perform archive and analytics in place.
IBM Spectrum Scale is a high-performance clustered file system developed as a software defined storage for big data analytics, and available for cloud and NAS solutions. It can be deployed in shared-disk or shared-nothing distributed parallel modes.
Spectrum Scale-based solutions by RAID Inc. are used by many of the world’s largest enterprises and supercomputers. Whether you have an existing Spectrum Scale system that is underperforming or are planning something new, RAID Inc. can help.